|
Yixiu Mao | 毛逸休 I'm a fifth-year Ph.D. student in the Department of Automation at Tsinghua University, advised by Prof. Xiangyang Ji. My research focuses on Reinforcement Learning and Large Reasoning Models. I work with the THU-IDM team, where we develop efficient algorithms for decision-making. Prior to my doctoral studies, I received my Bachelor's degree in Physics from Zhiyuan Honor College at Shanghai Jiao Tong University. |

|
News
|
ResearchI'm interested in Reinforcement Learning and Large Language Models. My research focuses on efficient and intelligent decision-making with minimal environment interactions. |
Selected Publications* denotes co-first authors |
|
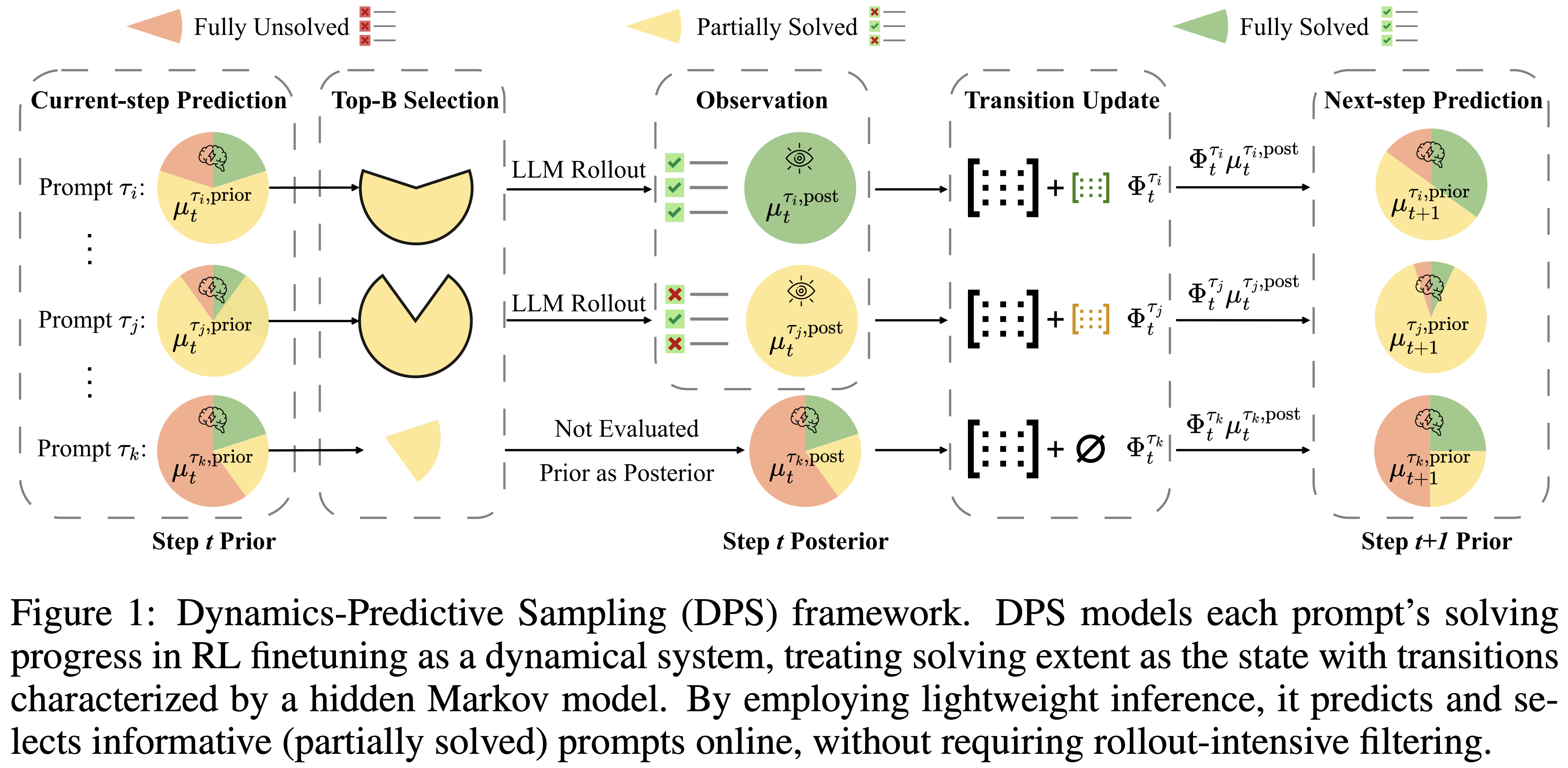
Dynamics-Predictive Sampling for Active RL Finetuning of Large Reasoning Models
Yixiu Mao, Yun Qu, Qi Wang, Heming Zou, Xiangyang Ji ICLR, 2026 Online predicts and selects informative prompts prior to rollout by inferring their learning dynamics, accelerating RL finetuning of large reasoning models. |
|
|
Adaptive Neighborhood-Constrained Q Learning for Offline Reinforcement Learning
Yixiu Mao, Yun Qu, Qi Wang, Xiangyang Ji NeurIPS, 2025 Spotlight paper / code A new constrained optimization paradigm for offline RL. |
|
|
Doubly Mild Generalization for Offline Reinforcement Learning
Yixiu Mao, Qi Wang, Yun Qu, Yuhang Jiang, Xiangyang Ji NeurIPS, 2024 paper / code Appropriately exploit generalization in offline RL. |
|
|
Offline Reinforcement Learning with OOD State Correction and OOD Action Suppression
Yixiu Mao, Qi Wang, Chen Chen, Yun Qu, Xiangyang Ji NeurIPS, 2024 paper / code A simple yet effective approach that unifies OOD state correction and OOD action suppression in offline RL. |
|
|
Supported Value Regularization for Offline Reinforcement Learning
Yixiu Mao, Hongchang Zhang, Chen Chen, Yi Xu, Xiangyang Ji NeurIPS, 2023 paper / code Theoretically grounded value regularization for offline RL. |
|
|
Supported Trust Region Optimization for Offline Reinforcement Learning
Yixiu Mao, Hongchang Zhang, Chen Chen, Yi Xu, Xiangyang Ji ICML, 2023 paper / code Theoretically grounded policy optimization for offline RL. |
|
|
In-Sample Actor Critic for Offline Reinforcement Learning
Hongchang Zhang*, Yixiu Mao*, Boyuan Wang, Shuncheng He, Yi Xu, Xiangyang Ji ICLR, 2023 paper In-sample learning for offline RL, avoiding extrapolation error. |
|
|
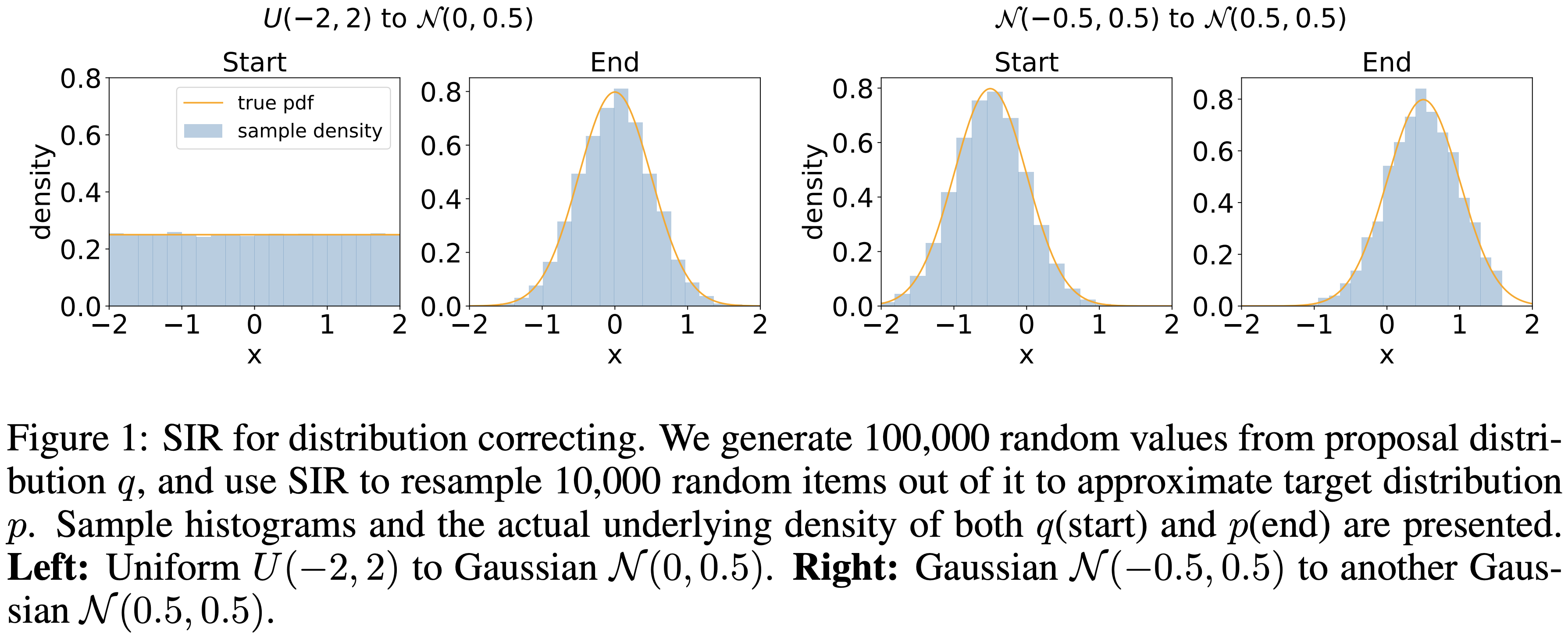
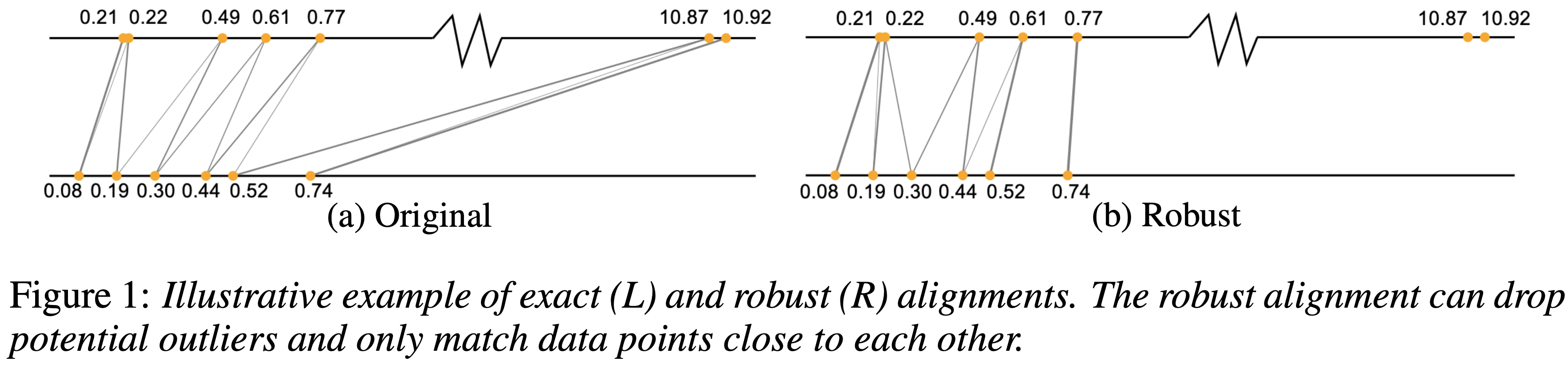
A Hypergradient Approach to Robust Regression without Correspondence
Yujia Xie*, Yixiu Mao*, Simiao Zuo, Hongteng Xu, Xiaojing Ye, Tuo Zhao, Hongyuan Zha ICLR, 2021 paper / code We consider a regression problem, where the correspondence between input and output data is not available. |
|
|
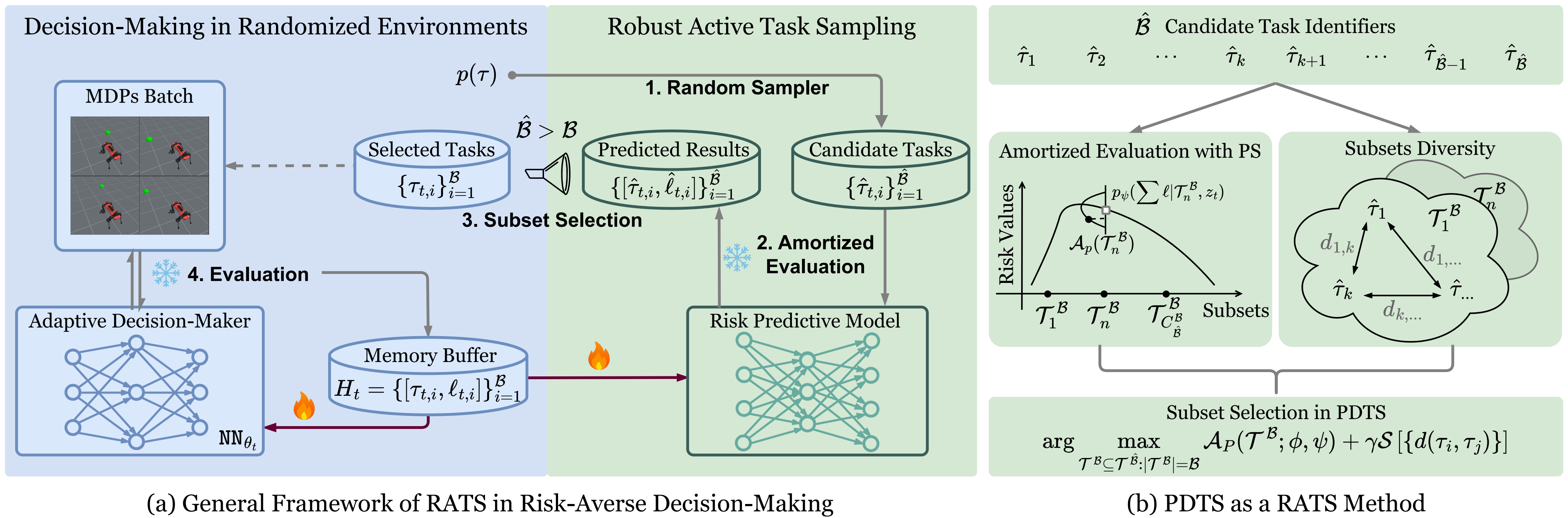
Fast and Robust: Task Sampling with Posterior and Diversity Synergies for Adaptive Decision-Makers in Randomized Environments
Yun Qu*, Qi Wang*, Yixiu Mao*, Yiqin Lv, Xiangyang Ji ICML, 2025 project page / paper / code We propose an easy-to-implement method, referred to as Posterior and Diversity Synergized Task Sampling (PDTS), to accommodate fast and robust sequential decision-making. |
|
|
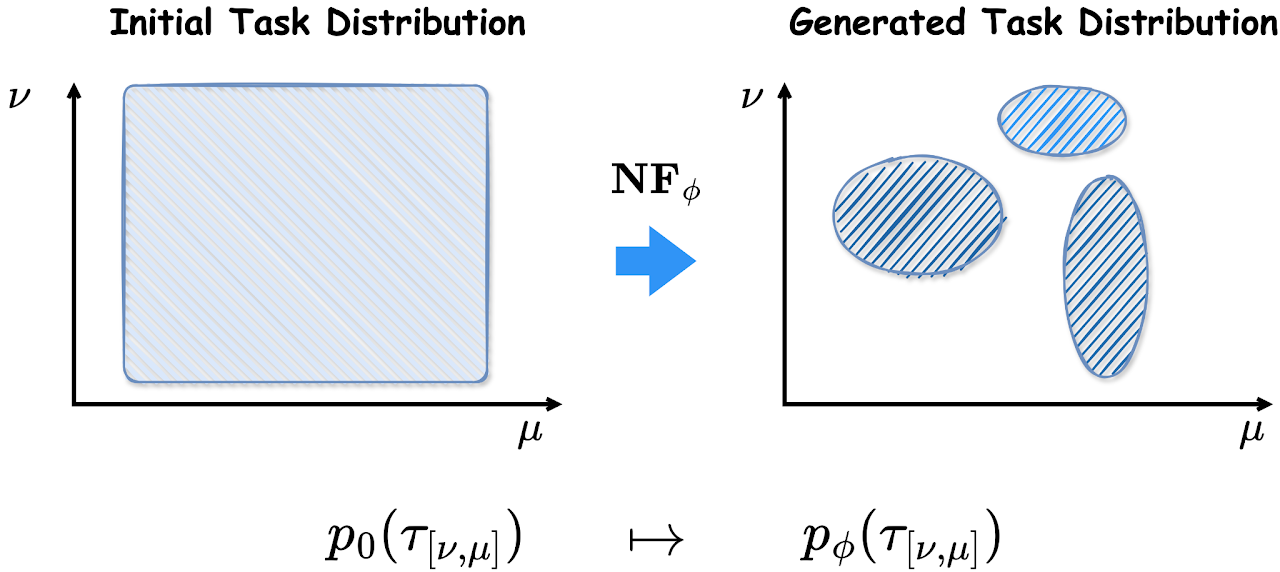
Robust Fast Adaptation from Adversarially Explicit Task Distribution Generation
Cheems Wang*, Yiqin Lv*, Yixiu Mao*, Yun Qu, Yi Xu, Xiangyang Ji KDD, 2025 project page / paper / code We consider explicitly generative modeling task distributions placed over task identifiers and propose robustifying fast adaptation from adversarial training. |
|
|
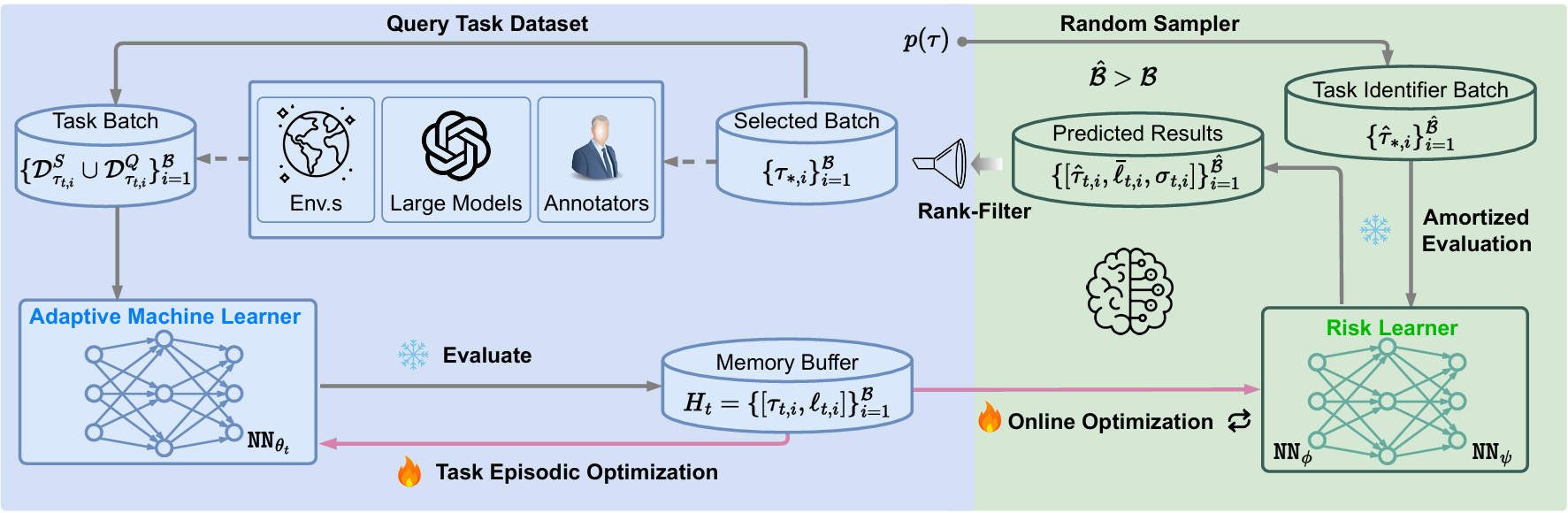
Model Predictive Task Sampling for Efficient and Robust Adaptation
Qi Wang*, Zehao Xiao*, Yixiu Mao*, Yun Qu*, Jiayi Shen, Yiqin Lv, Xiangyang Ji arxiv, 2025 paper / code We introduce Model Predictive Task Sampling (MPTS), a framework that bridges the task space and adaptation risk landscape, providing a theoretical foundation for robust active task sampling. |
|
|
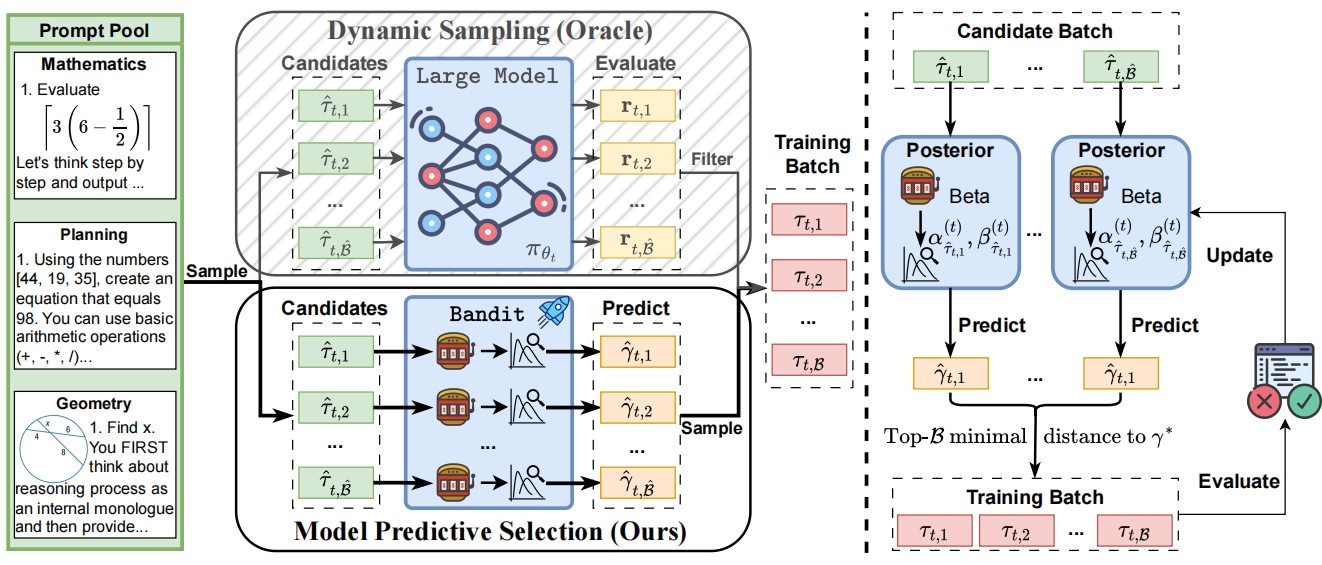
Can Prompt Difficulty be Online Predicted for Accelerating RL Finetuning of Reasoning Models?
Yun Qu, Qi Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, Xiangyang Ji KDD, 2026 paper / code This work introduces Model Predictive Prompt Selection, a Bayesian risk-predictive framework that online estimates prompt difficulty without requiring costly LLM interactions. |
|
|
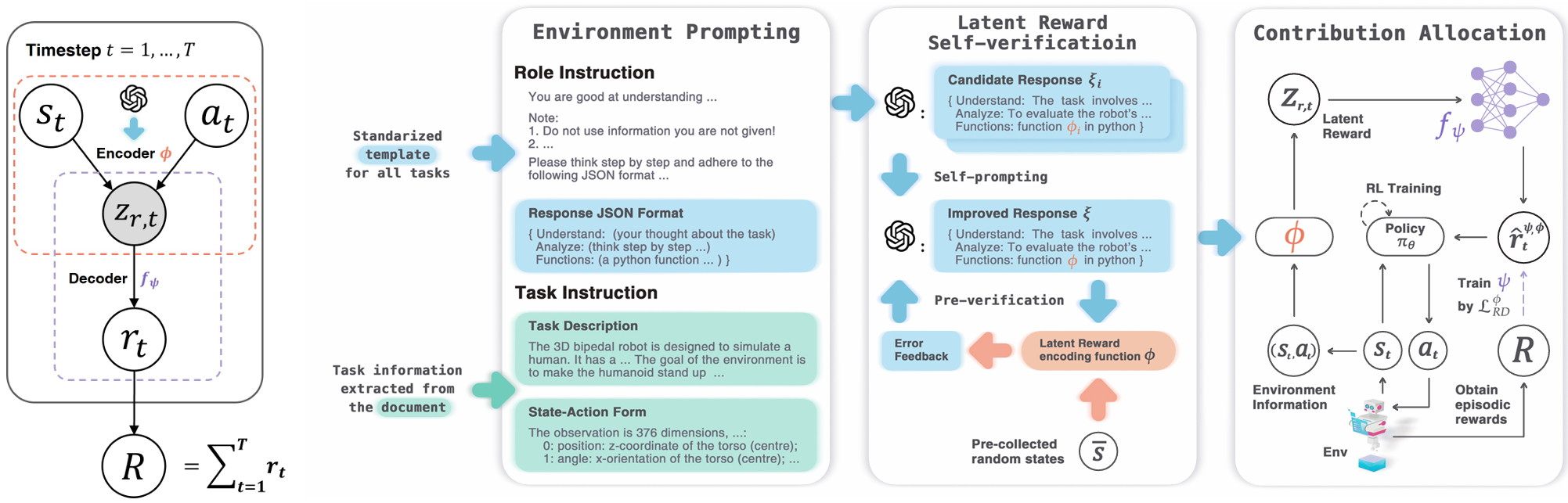
Latent Reward: LLM-Empowered Credit Assignment in Episodic Reinforcement Learning
Yun Qu*, Yuhang Jiang*, Boyuan Wang, Yixiu Mao, Qi Wang, Chang Liu, Xiangyang Ji AAAI, 2025 paper / code We introduce LaRe, a novel LLM-empowered symbolic-based decision-making framework, to improve credit assignment in episodic reinforcement learning. |
|
|
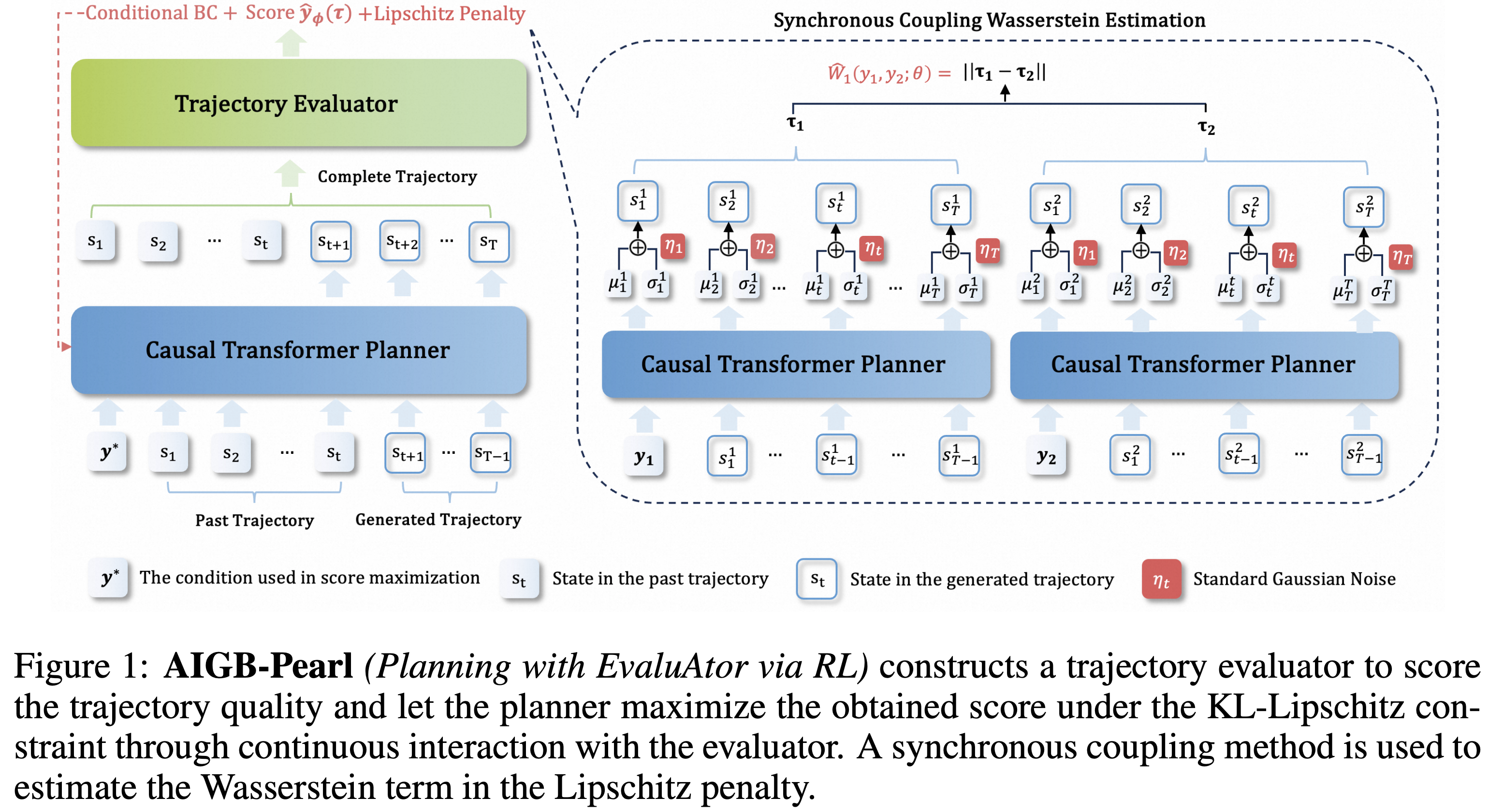
Enhancing Generative Auto-bidding with Offline Reward Evaluation and Policy Search
Zhiyu Mou, Yiqin Lv, Miao Xu, Qi Wang, Yixiu Mao, Qichen Ye, Chao Li, Rongquan Bai, Chuan Yu, Jian Xu, Bo Zheng ICLR, 2026 Oral paper
|



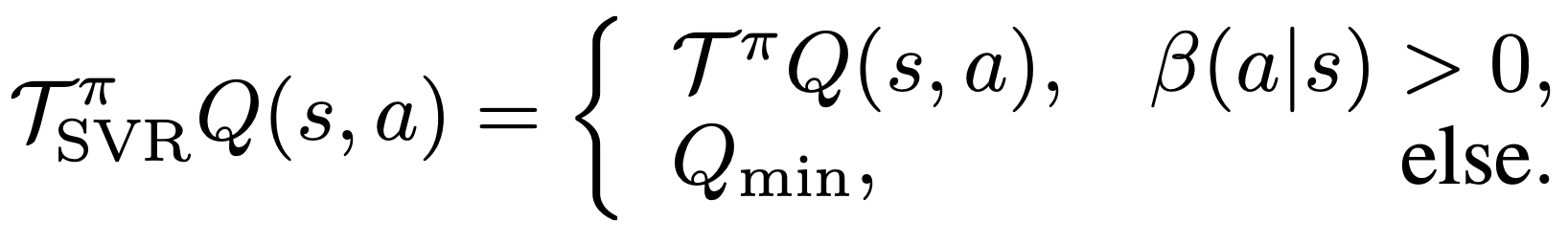

|
Website template from Jon Barron |